

Large language models are typically refined after pretraining using either supervised fine-tuning (SFT) or reinforcement fine-tuning (RFT), each with distinct strengths and limitations. SFT is effective in teaching instruction-following through example-based learning, but it can lead to rigid behavior and poor generalization. RFT, on the other hand, optimizes models for task success using reward signals, which can improve performance but also introduce instability and reliance on a strong starting policy. While these methods are often used sequentially, their interaction remains poorly understood. This raises an important question: how can we design a unified framework that combines SFT’s structure with RFT’s goal-driven learning?
Research at the intersection of RL and LLM post-training has gained momentum, particularly for training reasoning-capable models. Offline RL, which learns from fixed datasets, often yields suboptimal policies due to the limited diversity of the data. This has sparked interest in combining offline and online RL approaches to improve performance. In LLMs, the dominant strategy is to first apply SFT to teach desirable behaviors, then use RFT to optimize outcomes. However, the dynamics between SFT and RFT are still not well understood, and finding effective ways to integrate them remains an open research challenge.
Researchers from the University of Edinburgh, Fudan University, Alibaba Group, Stepfun, and the University of Amsterdam propose a unified framework that combines supervised and reinforcement fine-tuning in a way called Prefix-RFT. This method guides exploration using partial demonstrations, allowing the model to continue generating solutions with flexibility and adaptability. Tested on math reasoning tasks, Prefix-RFT consistently outperforms standalone SFT, RFT, and mixed-policy methods. It integrates easily into existing frameworks and proves robust to changes in demonstration quality and quantity. Blending demonstration-based learning with exploration can lead to more effective and adaptive training of large language models.
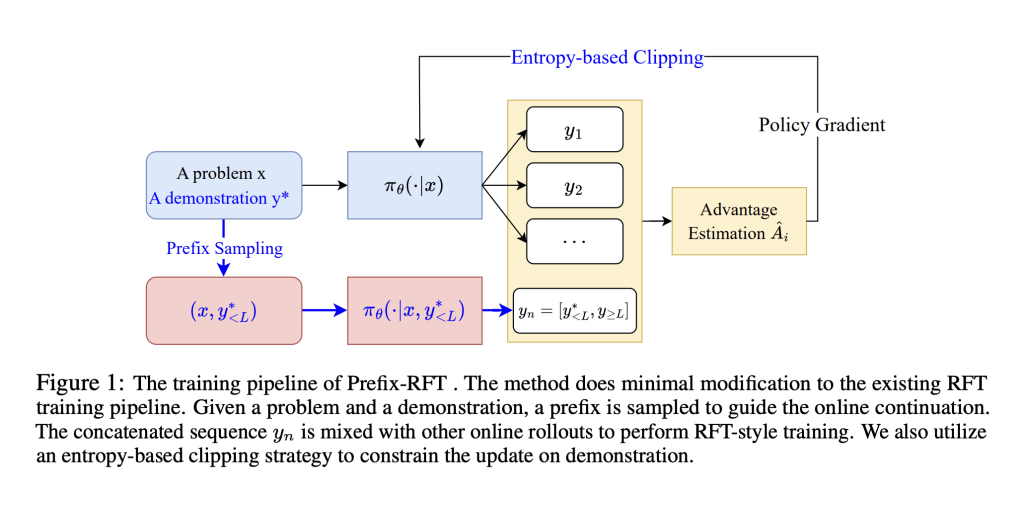
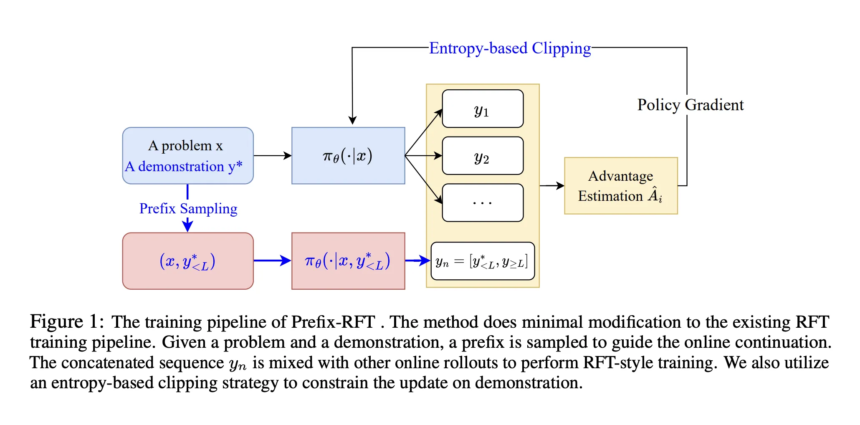
The study presents Prefix Reinforcement Fine-Tuning (Prefix-RFT) as a way to blend the strengths of SFT and RFT. While SFT offers stability by mimicking expert demonstrations, RFT encourages exploration through the use of reward signals. Prefix-RFT bridges the two by using a partial demonstration (a prefix) and letting the model generate the rest. This approach guides learning without relying too heavily on full supervision. It incorporates techniques like entropy-based clipping and a cosine decay scheduler to ensure stable training and efficient learning. Compared to prior methods, Prefix-RFT offers a more balanced and adaptive fine-tuning strategy.
Prefix-RFT is a reward fine-tuning method that improves performance using high-quality offline math datasets, such as OpenR1-Math-220K (46k filtered problems). Tested on Qwen2.5-Math-7B, 1.5B, and LLaMA-3.1-8B, it was evaluated on benchmarks including AIME 2024/25, AMC, MATH500, Minerva, and OlympiadBench. Prefix-RFT achieved the highest avg@32 and pass@1 scores across tasks, outperforming RFT, SFT, ReLIFT, and LUFFY. Using Dr. GRPO, it updated only the top 20% high-entropy prefix tokens, with the prefix length decaying from 95% to 5%. It maintained intermediate SFT loss, indicating a strong balance between imitation and exploration, especially on difficult problems (Trainhard).

In conclusion, Prefix-RFT combines the strengths of SFT and RFT by utilizing sampled demonstration prefixes to guide learning. Despite its simplicity, it consistently outperforms SFT, RFT, and hybrid baselines across various models and datasets. Even with only 1% of the training data (450 prompts), it maintains strong performance (avg@32 drops only from 40.8 to 37.6), showing efficiency and robustness. Its top-20% entropy-based token update strategy proves most effective, achieving the highest benchmark scores with shorter outputs. Moreover, using a cosine decay scheduler for prefix length enhances stability and learning dynamics compared to a uniform strategy, particularly on complex tasks such as AIME.
Check out the Paper here. Feel free to check out our GitHub Page for Tutorials, Codes and Notebooks. Also, feel free to follow us on Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter.
Sana Hassan, a consulting intern at Marktechpost and dual-degree student at IIT Madras, is passionate about applying technology and AI to address real-world challenges. With a keen interest in solving practical problems, he brings a fresh perspective to the intersection of AI and real-life solutions.





