

Allen Institute for AI (AI2) is releasing Olmo 3 as a fully open model family that exposes the entire ‘model flow’, from raw data and code to intermediate checkpoints and deployment ready variants.
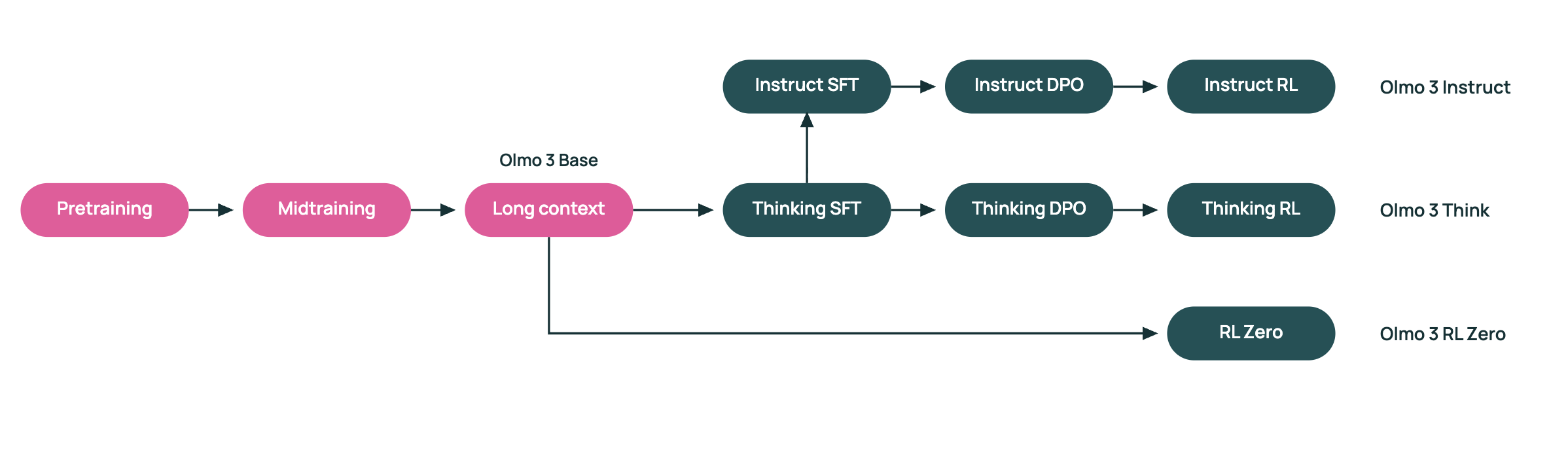
Olmo 3 is a dense transformer suite with 7B and 32B parameter models. The family includes Olmo 3-Base, Olmo 3-Think, Olmo 3-Instruct, and Olmo 3-RL Zero. Both 7B and 32B variants share a context length of 65,536 tokens and use the same staged training recipe.
Dolma 3 Data Suite
At the core of the training pipeline is Dolma 3, a new data collection designed for Olmo 3. Dolma 3 consists of Dolma 3 Mix, Dolma 3 Dolmino Mix, and Dolma 3 Longmino Mix. Dolma 3 Mix is a 5.9T token pre training dataset with web text, scientific PDFs, code repositories, and other natural data. The Dolmino and Longmino subsets are constructed from filtered, higher quality slices of this pool.
Dolma 3 Mix supports the main pre training stage for Olmo 3-Base. AI2 research team then applies Dolma 3 Dolmino Mix, a 100B token mid training set that emphasizes math, code, instruction following, reading comprehension, and thinking oriented tasks. Finally, Dolma 3 Longmino Mix adds 50B tokens for the 7B model and 100B tokens for the 32B model, with a strong focus on long documents and scientific PDFs processed with the olmOCR pipeline. This staged curriculum is what pushes the context limit to 65,536 tokens while maintaining stability and quality.
Large Scale Training on H100 Clusters
Olmo 3-Base 7B trains on Dolma 3 Mix using 1,024 H100 devices, reaching about 7,700 tokens per device per second. Later stages use 128 H100s for Dolmino mid training and 256 H100s for Longmino long context extension.
Base Model Performance Against Open Families
On standard capability benchmarks, Olmo 3-Base 32B is positioned as a leading fully open base model. AI2 research team reports that it is competitive with prominent open weight families such as Qwen 2.5 and Gemma 3 at similar sizes. Compared across a wide suite of tasks, Olmo 3-Base 32B ranks near or above these models while keeping the full data and training configuration open for inspection and reuse.
Reasoning Focused Olmo 3 Think
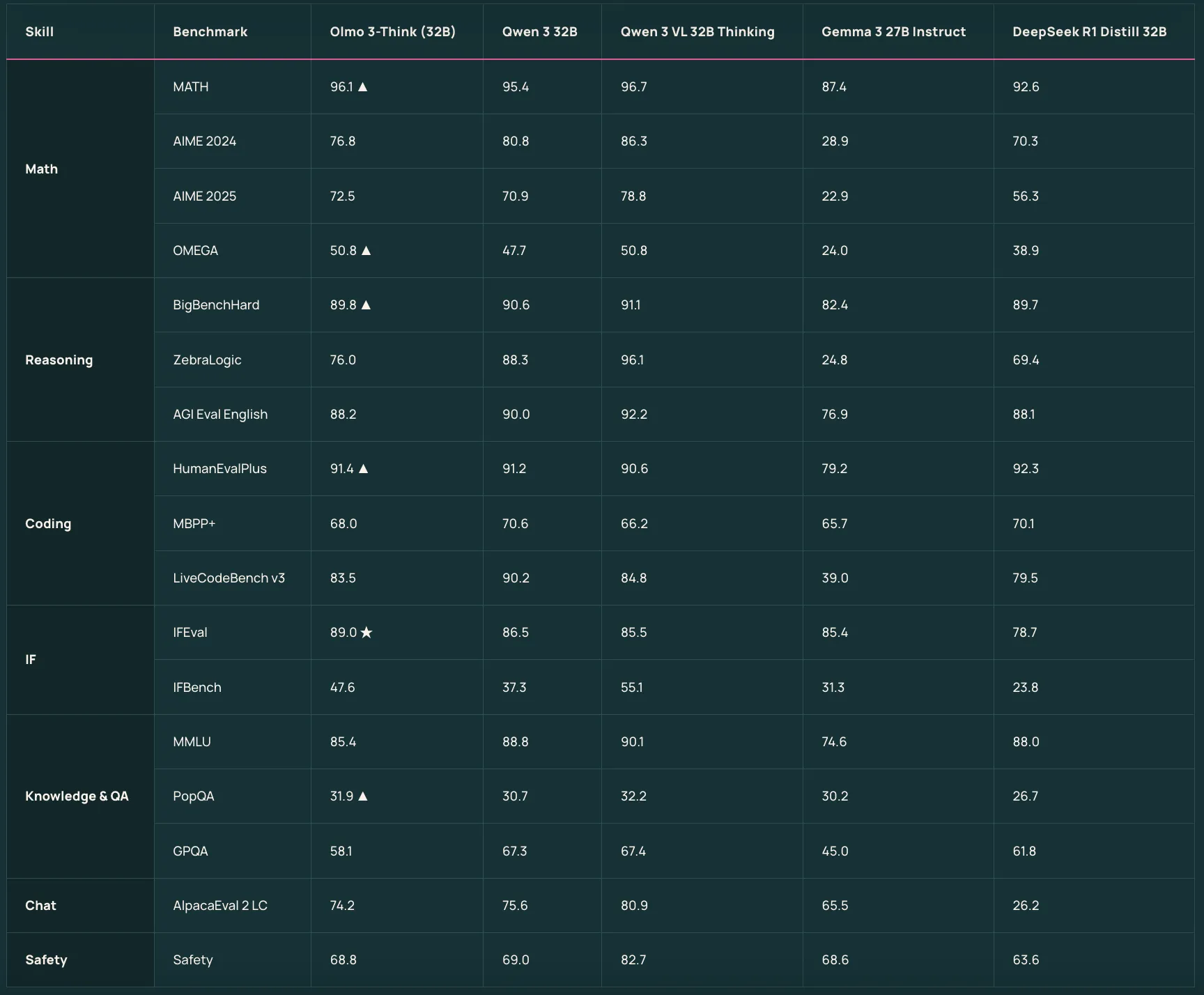
Olmo 3-Think 7B and Olmo 3-Think 32B sit on top of the base models as reasoning focused variants. They use a three stage post training recipe that includes supervised fine tuning, Direct Preference Optimization, and Reinforcement Learning with Verifiable Rewards within the OlmoRL framework. Olmo 3-Think 32B is described as the strongest fully open reasoning model and it narrows the gap to Qwen 3 32B thinking models while using about six times fewer training tokens.
Olmo 3 Instruct for Chat and Tool Use
Olmo 3-Instruct 7B is tuned for fast instruction following, multi turn chat, and tool use. It starts from Olmo 3-Base 7B and applies a separate Dolci Instruct data and training pipeline that covers supervised fine tuning, DPO, and RLVR for conversational and function calling workloads. AI2 research team reports that Olmo 3-Instruct matches or outperforms open weight competitors such as Qwen 2.5, Gemma 3, and Llama 3.1 and is competitive with Qwen 3 families at similar scales for several instruction and reasoning benchmarks.
RL Zero for Clean RL Research
Olmo 3-RL Zero 7B is designed for researchers who care about reinforcement learning on language models but need clean separation between pre training data and RL data. It is built as a fully open RL pathway on top of Olmo 3-Base and uses Dolci RL Zero datasets that are decontaminated with respect to Dolma 3.
Comparison Table
| Model variant | Training or post training data | Primary use case | Reported position vs other open models |
|---|---|---|---|
| Olmo 3 Base 7B | Dolma 3 Mix pre training, Dolma 3 Dolmino Mix mid training, Dolma 3 Longmino Mix long context | General foundation model, long context reasoning, code, math | Strong fully open 7B base, designed as foundation for Think, Instruct, RL Zero, evaluated against leading open 7B scale bases |
| Olmo 3 Base 32B | Same Dolma 3 staged pipeline as 7B, with 100B Longmino tokens for long context | High end base for research, long context workloads, RL setups | Described as the best fully open 32B base, comparable to Qwen 2.5 32B and Gemma 3 27B and outperforming Marin, Apertus, LLM360 |
| Olmo 3 Think 7B | Olmo 3 Base 7B, plus Dolci Think SFT, Dolci Think DPO, Dolci Think RL in OlmoRL framework | Reasoning focused 7B model with internal thinking traces | Fully open reasoning model at efficient scale that enables chain of thought research and RL experiments on modest hardware |
| Olmo 3 Think 32B | Olmo 3 Base 32B, plus the same Dolci Think SFT, DPO, RL pipeline | Flagship reasoning model with long thinking traces | Stated as the strongest fully open thinking model, competitive with Qwen 3 32B thinking models while training on about 6x fewer tokens |
| Olmo 3 Instruct 7B | Olmo 3 Base 7B, plus Dolci Instruct SFT, Dolci Instruct DPO, Dolci Instruct RL 7B | Instruction following, chat, function calling, tool use | Reported to outperform Qwen 2.5, Gemma 3, Llama 3 and to narrow the gap to Qwen 3 families at similar scale |
| Olmo 3 RL Zero 7B | Olmo 3 Base 7B, plus Dolci RLZero Math, Code, IF, Mix datasets, decontaminated from Dolma 3 | RLVR research on math, code, instruction following, mixed tasks | Introduced as a fully open RL pathway for benchmarking RLVR on top of a base model with fully open pre training data |
Key Takeaways
- End to end transparent pipeline: Olmo 3 exposes the full ‘model flow’ from Dolma 3 data construction, through staged pre training and post training, to released checkpoints, evaluation suites, and tooling, enabling fully reproducible LLM research and fine grained debugging.
- Dense 7B and 32B models with 65K context: The family covers 7B and 32B dense transformers, all with a 65,536 token context window, trained via a three stage Dolma 3 curriculum, Dolma 3 Mix for main pre training, Dolma 3 Dolmino for mid training, and Dolma 3 Longmino for long context extension.
- Strong open base and reasoning models: Olmo 3 Base 32B is positioned as a top fully open base model at its scale, competitive with Qwen 2.5 and Gemma 3, while Olmo 3 Think 32B is described as the strongest fully open thinking model and approaches Qwen 3 32B thinking models using about 6 times fewer training tokens.
- Task tuned Instruct and RL Zero variants: Olmo 3 Instruct 7B targets instruction following, multi turn chat, and tool use using Dolci Instruct SFT, DPO, and RLVR data, and is reported to match or outperform Qwen 2.5, Gemma 3, and Llama 3.1 at similar scale. Olmo 3 RL Zero 7B provides a fully open RLVR pathway with Dolci RLZero datasets decontaminated from pre training data for math, code, instruction following, and general chat.
Olmo 3 is an unusual release because it operationalizes openness across the full stack, Dolma 3 data recipes, staged pre training, Dolci post training, RLVR in OlmoRL, and evaluation with OLMES and OlmoBaseEval. This reduces ambiguity around data quality, long context training, and reasoning oriented RL, and it creates a concrete baseline for extending Olmo 3 Base, Olmo 3 Think, Olmo 3 Instruct, and Olmo 3 RL Zero in controlled experiments. Overall, Olmo 3 sets a rigorous reference point for transparent, research grade LLM pipelines.
Check out the Technical details. Feel free to check out our GitHub Page for Tutorials, Codes and Notebooks. Also, feel free to follow us on Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter. Wait! are you on telegram? now you can join us on telegram as well.

Michal Sutter is a data science professional with a Master of Science in Data Science from the University of Padova. With a solid foundation in statistical analysis, machine learning, and data engineering, Michal excels at transforming complex datasets into actionable insights.




