How do you get GPT-5-level reasoning on real long-context, tool-using workloads without paying the quadratic attention and GPU cost that usually makes those systems impractical? DeepSeek research introduces DeepSeek-V3.2 and DeepSeek-V3.2-Speciale. They are reasoning-first models built for agents and targets high quality reasoning, long context and agent workflows, with open weights and production APIs. The models combine DeepSeek Sparse Attention (DSA), a scaled GRPO reinforcement learning stack and an agent native tool protocol, and report performance comparable to GPT 5, with DeepSeek-V3.2-Speciale reaching Gemini 3.0 Pro level reasoning on public benchmarks and competitions.
Sparse Attention with Near Linear Long Context Cost
Both DeepSeek-V3.2 and DeepSeek-V3.2-Speciale use the DeepSeek-V3 Mixture of Experts transformer with about 671B total parameters and 37B active parameters per token, inherited from V3.1 Terminus. The only structural change is DeepSeek Sparse Attention, introduced through continued pre-training.
DeepSeek Sparse Attention splits attention into 2 components. A lightning indexer runs a small number of low precision heads over all token pairs and produces relevance scores. A fine grained selector keeps the top-k-key value positions per query, and the main attention path runs Multi-Query-Attention and Multi-Head-Latent-Attention on this sparse set.
This changes the dominant complexity from O(L²) to O(kL), where L is sequence length and k is the number of selected tokens and much smaller than L. Based on the benchmarks, DeepSeek-V3.2 matches the dense Terminus baseline on accuracy while reducing long context inference cost by about 50 percent, with faster throughput and lower memory use on H800 class hardware and on vLLM and SGLang backends.

Continued Pre Training for DeepSeek Sparse Attention
DeepSeek Sparse Attention (DSA) is introduced by continued pre-training on top of DeepSeek-V3.2 Terminus. In the dense warm up stage, dense attention remains active, all backbone parameters are frozen and only the lightning indexer is trained with a Kullback Leibler loss to match the dense attention distribution on 128K context sequences. This stage uses a small number of steps and about 2B tokens, enough for the indexer to learn useful scores.
In the sparse stage, the selector keeps 2048 key-value entries per query, the backbone is unfrozen and the model continues training on about 944B tokens. Gradients for the indexer still come only from the alignment loss with dense attention on the selected positions. This schedule makes DeepSeek Sparse Attention (DSA) behave as a drop in replacement for dense attention with similar quality and lower long context cost.

GRPO with more than 10 Percent RL Compute
On top of the sparse architecture, DeepSeek-V3.2 uses Group Relative Policy Optimization (GRPO) as the main reinforcement learning method. The research team state that post training reinforcement learning RL compute exceeds 10 percent of pre training compute.
RL is organized around specialist domains. The research team trains dedicated runs for mathematics, competitive programming, general logical reasoning, browsing and agent tasks and safety, then distills these specialists into the shared 685B parameter base for DeepSeek-V3.2 and DeepSeek-V3.2-Speciale. GRPO is implemented with an unbiased KL estimator, off policy sequence masking and mechanisms that keep Mixture of Experts (MoE) routing and sampling masks consistent between training and sampling.

Agent Data, Thinking Mode and Tool Protocol
DeepSeek research team builds a large synthetic agent dataset by generating more than 1,800 environments and more than 85,000 tasks across code agents, search agents, general tools and code interpreter setups. Tasks are constructed to be hard to solve and easy to verify, and are used as RL targets together with real coding and search traces.
At inference time, DeepSeek-V3.2 introduces explicit thinking and non thinking modes. The deepseek-reasoner endpoint exposes thinking mode by default, where the model produces an internal chain of thought before the final answer. The thinking with tools guide describes how reasoning content is kept across tool calls and cleared when a new user message arrives, and how tool calls and tool results stay in the context even when reasoning text is trimmed for budget.
The chat template is updated around this behavior. The DeepSeek-V3.2 Speciale repository ships Python encoder and decoder helpers instead of a Jinja template. Messages can carry a reasoning_content field alongside content, controlled by a thinking parameter. A developer role is reserved for search agents and is not accepted in general chat flows by the official API, which protects this channel from accidental misuse.

Benchmarks, Competitions And Open Artifacts
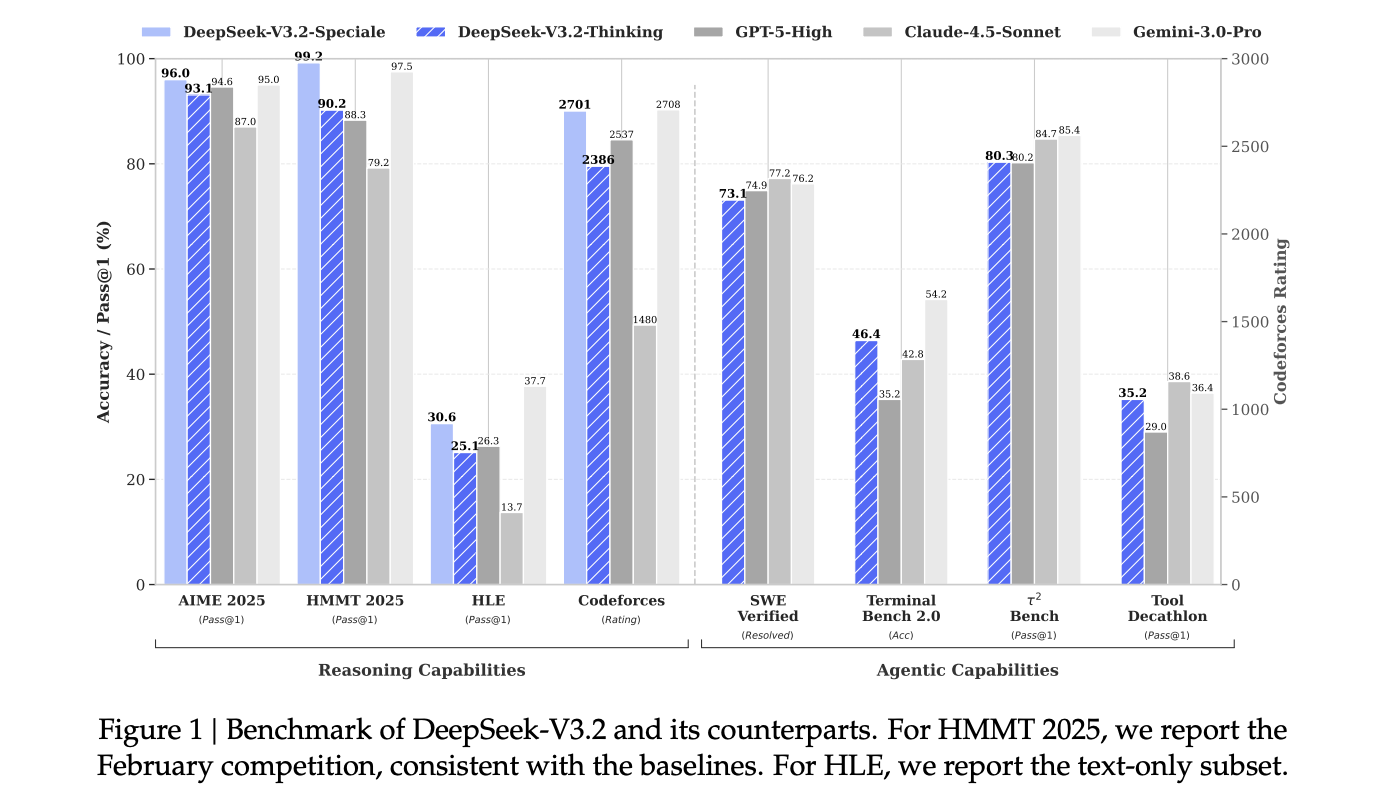
On standard reasoning and coding benchmarks, DeepSeek-V3.2 and especially DeepSeek-V3.2 Speciale are reported as comparable to GPT-5 and close to Gemini-3.0 Pro on suites such as AIME 2025, HMMT 2025, GPQA and LiveCodeBench, with improved cost efficiency on long context workloads.
For formal competitions, DeepSeek research team states that DeepSeek-V3.2 Speciale achieves gold medal level performance on the International Mathematical Olympiad 2025, the Chinese Mathematical Olympiad 2025 and the International Olympiad in Informatics 2025, and competitive gold medal level performance at the ICPC World Finals 2025.
Key Takeaways
- DeepSeek-V3.2 adds DeepSeek Sparse Attention, which brings near linear O(kL) attention cost and delivers around 50% lower long context API cost compared to previous dense DeepSeek models, while keeping quality similar to DeepSeek-V3.1 Terminus.
- The model family keeps the 671B parameter MoE backbone with 37B active parameters per token and exposes a full 128K context window in production APIs, which makes long documents, multi step chains and large tool traces practical rather than a lab only feature.
- Post training uses Group Relative Policy Optimization (GRPO) with a compute budget that is more than 10 percent of pre-training, focused on math, code, general reasoning, browsing or agent workloads and safety, along with contest style specialists whose cases are released for external verification.
- DeepSeek-V3.2 is the first model in the DeepSeek family to integrate thinking directly into tool use, supporting both thinking and non thinking tool modes and a protocol where internal reasoning persists across tool calls and is reset only on new user messages.
Check out the Paper and Model weights. Feel free to check out our GitHub Page for Tutorials, Codes and Notebooks. Also, feel free to follow us on Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter. Wait! are you on telegram? now you can join us on telegram as well.
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of Artificial Intelligence for social good. His most recent endeavor is the launch of an Artificial Intelligence Media Platform, Marktechpost, which stands out for its in-depth coverage of machine learning and deep learning news that is both technically sound and easily understandable by a wide audience. The platform boasts of over 2 million monthly views, illustrating its popularity among audiences.