


Question:
You’re deploying an LLM in production. Generating the first few tokens is fast, but as the sequence grows, each additional token takes progressively longer to generate—even though the model architecture and hardware remain the same.
If compute isn’t the primary bottleneck, what inefficiency is causing this slowdown, and how would you redesign the inference process to make token generation significantly faster?
What is KV Caching and how does it make token generation faster?
KV caching is an optimization technique used during text generation in large language models to avoid redundant computation. In autoregressive generation, the model produces text one token at a time, and at each step it normally recomputes attention over all previous tokens. However, the keys (K) and values (V) computed for earlier tokens never change.
With KV caching, the model stores these keys and values the first time they are computed. When generating the next token, it reuses the cached K and V instead of recomputing them from scratch, and only computes the query (Q), key, and value for the new token. Attention is then calculated using the cached information plus the new token.
This reuse of past computations significantly reduces redundant work, making inference faster and more efficient—especially for long sequences—at the cost of additional memory to store the cache. Check out the Practice Notebook here

Evaluating the Impact of KV Caching on Inference Speed
In this code, we benchmark the impact of KV caching during autoregressive text generation. We run the same prompt through the model multiple times, once with KV caching enabled and once without it, and measure the average generation time. By keeping the model, prompt, and generation length constant, this experiment isolates how reusing cached keys and values significantly reduces redundant attention computation and speeds up inference. Check out the Practice Notebook here
import numpy as np
import time
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
device = "cuda" if torch.cuda.is_available() else "cpu"
model_name = "gpt2-medium"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name).to(device)
prompt = "Explain KV caching in transformers."
inputs = tokenizer(prompt, return_tensors="pt").to(device)
for use_cache in (True, False):
times = []
for _ in range(5):
start = time.time()
model.generate(
**inputs,
use_cache=use_cache,
max_new_tokens=1000
)
times.append(time.time() - start)
print(
f"{'with' if use_cache else 'without'} KV caching: "
f"{round(np.mean(times), 3)} ± {round(np.std(times), 3)} seconds"
)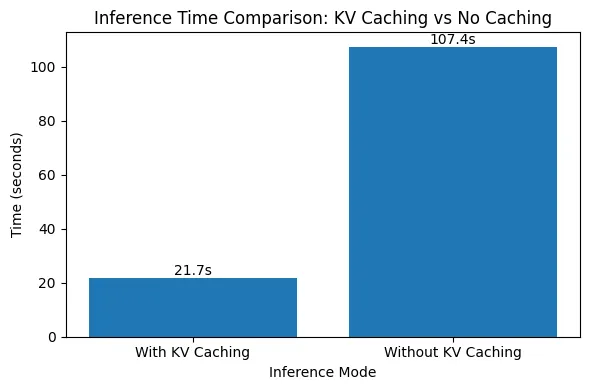
The results clearly demonstrate the impact of KV caching on inference speed. With KV caching enabled, generating 1000 tokens takes around 21.7 seconds, whereas disabling KV caching increases the generation time to over 107 seconds—nearly a 5× slowdown. This sharp difference occurs because, without KV caching, the model recomputes attention over all previously generated tokens at every step, leading to quadratic growth in computation. Check out the Practice Notebook here
With KV caching, past keys and values are reused, eliminating redundant work and keeping generation time nearly linear as the sequence grows. This experiment highlights why KV caching is essential for efficient, real-world deployment of autoregressive language models.
Check out the Practice Notebook here

I am a Civil Engineering Graduate (2022) from Jamia Millia Islamia, New Delhi, and I have a keen interest in Data Science, especially Neural Networks and their application in various areas.





