

Embodied AI agents that can perceive, think, and act in the real world mark a key step toward the future of robotics. A central challenge is building scalable, reliable robotic manipulation, the skill of deliberately interacting with and controlling objects through selective contact. While progress spans analytic methods, model-based approaches, and large-scale data-driven learning, most systems still operate in disjoint stages of data collection, training, and evaluation. These stages often require custom setups, manual curation, and task-specific tweaks, creating friction that slows progress, hides failure patterns, and hampers reproducibility. This highlights the need for a unified framework to streamline learning and assessment.
Robotic manipulation research has progressed from analytical models to neural world models that learn dynamics directly from sensory inputs, using both pixel and latent spaces. Large-scale video generation models can produce realistic visuals but often lack action conditioning, long-term temporal consistency, and multi-view reasoning needed for control. Vision-language-action models follow instructions but are limited by imitation-based learning, preventing error recovery and planning. Policy evaluation remains challenging, as physics simulators require heavy tuning, and real-world testing is resource-intensive. Existing evaluation metrics often emphasize visual quality over task success, highlighting the need for benchmarks that better capture real-world manipulation performance.
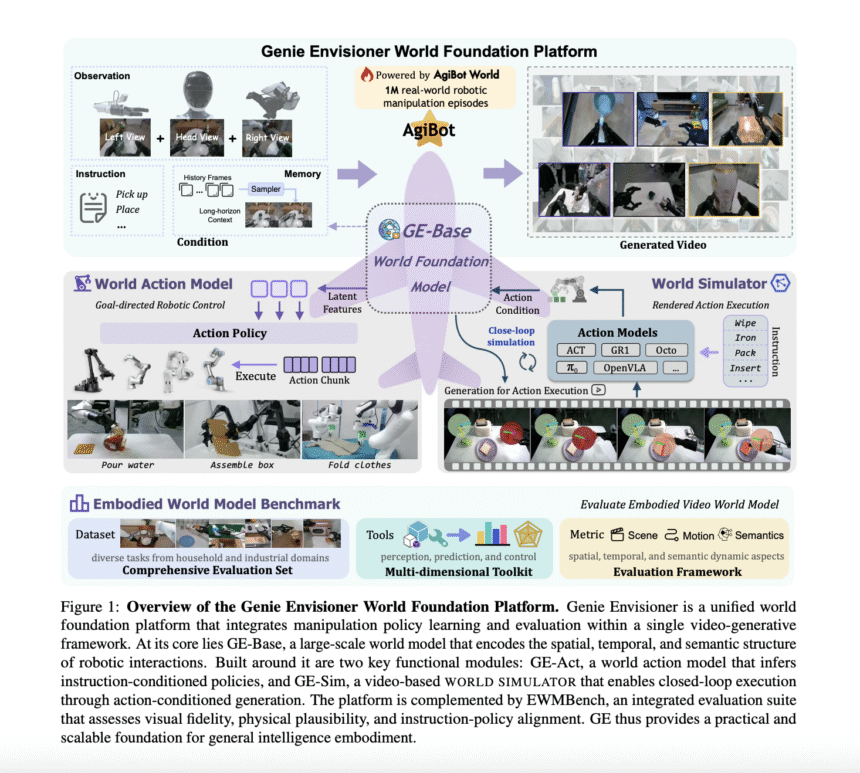
The Genie Envisioner (GE), developed by researchers from AgiBot Genie Team, NUS LV-Lab, and BUAA, is a unified platform for robotic manipulation that combines policy learning, simulation, and evaluation in a video-generative framework. Its core, GE-Base, is a large-scale, instruction-driven video diffusion model capturing spatial, temporal, and semantic dynamics of real-world tasks. GE-Act maps these representations to precise action trajectories, while GE-Sim offers fast, action-conditioned video-based simulation. The EWMBench benchmark evaluates visual realism, physical accuracy, and instruction-action alignment. Trained on over a million episodes, GE generalizes across robots and tasks, enabling scalable, memory-aware, and physically grounded embodied intelligence research.
GE’s design unfolds in three key parts. GE-Base is a multi-view, instruction-conditioned video diffusion model trained on over 1 million robotic manipulation episodes. It learns latent trajectories that capture how scenes evolve under given commands. Building on that, GE-Act translates these latent video representations into real action signals via a lightweight, flow-matching decoder, offering quick, precise motor control even on robots not in the training data. GE-Sim repurposes GE-Base’s generative power into an action-conditioned neural simulator, enabling closed-loop, video-based rollout at speeds far beyond real hardware. The EWMBench suite then evaluates the system holistically across video realism, physical consistency, and alignment between instructions and resulting actions.
In evaluations, Genie Envisioner showed strong real-world and simulated performance across varied robotic manipulation tasks. GE-Act achieved rapid control generation (54-step trajectories in 200 ms) and consistently outperformed leading vision-language-action baselines in both step-wise and end-to-end success rates. It adapted to new robot types, like Agilex Cobot Magic and Dual Franka, with only an hour of task-specific data, excelling in complex deformable object tasks. GE-Sim delivered high-fidelity, action-conditioned video simulations for scalable, closed-loop policy testing. The EWMBench benchmark confirmed GE-Base’s superior temporal alignment, motion consistency, and scene stability over state-of-the-art video models, aligning closely with human quality judgments.

In conclusion, Genie Envisioner is a unified, scalable platform for dual-arm robotic manipulation that merges policy learning, simulation, and evaluation into one video-generative framework. Its core, GE-Base, is an instruction-guided video diffusion model capturing the spatial, temporal, and semantic patterns of real-world robot interactions. GE-Act builds on this by converting these representations into precise, adaptable action plans, even on new robot types with minimal retraining. GE-Sim offers high-fidelity, action-conditioned simulation for closed-loop policy refinement, while EWMBench provides rigorous evaluation of realism, alignment, and consistency. Extensive real-world tests highlight the system’s superior performance, making it a strong foundation for general-purpose, instruction-driven embodied intelligence.
Check out the Paper and GitHub Page. Feel free to check out our GitHub Page for Tutorials, Codes and Notebooks. Also, feel free to follow us on Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter.
Sana Hassan, a consulting intern at Marktechpost and dual-degree student at IIT Madras, is passionate about applying technology and AI to address real-world challenges. With a keen interest in solving practical problems, he brings a fresh perspective to the intersection of AI and real-life solutions.





