

Contrastive Language-Image Pre-training (CLIP) has become important for modern vision and multimodal models, enabling applications such as zero-shot image classification and serving as vision encoders in MLLMs. However, most CLIP variants, including Meta CLIP, are limited to English-only data curation, ignoring a significant amount of non-English content from the worldwide web. Scaling CLIP to include multilingual data has two challenges: (a) the lack of an efficient method to curate non-English data at scale and (b) the decline of English performance when adding multilingual data, also known as the curse of multilinguality. These issues hinder the development of unified models optimized for both English and non-English tasks.
Methods like OpenAI CLIP and Meta CLIP depend on English-centric curation, and distillation-based approaches introduce biases from external teacher models. SigLIP and SigLIP 2 attempt to utilize data from Google Image Search, but their dependency on proprietary sources limits scalability. Multilingual CLIP models, such as M-CLIP and mCLIP, adopt distillation techniques, using English-only CLIP as a vision encoder and training multilingual text encoders with low-quality data. Moreover, hybrid methods such as SLIP and LiT combine language supervision with self-supervised learning (SSL) for balancing semantic alignment and visual representation. Despite these efforts, none of the methods has resolved the core issues.
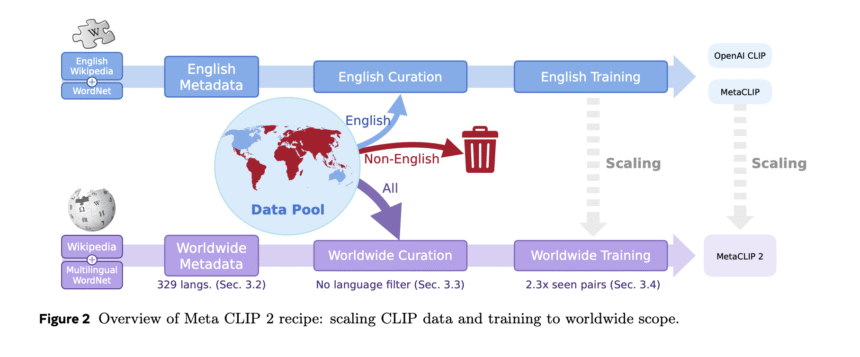
Researchers from Meta, MIT, Princeton University, and New York University have proposed Meta CLIP 2, the first method to train CLIP models from scratch using native worldwide image-text pairs without relying on external resources like private data, machine translation, or distillation. It removes the performance trade-offs between English and non-English data by designing and jointly scaling metadata, data curation, model capacity, and training. Meta CLIP 2 maximizes compatibility with OpenAI CLIP’s architecture, ensuring generalizability to CLIP and its variants. Moreover, its recipe introduces three innovations for scaling to worldwide: (a) scalable metadata across 300+ languages, (b) a per-language curation algorithm for balanced concept distribution, and (c) an advanced training framework.

To address the first challenge, researchers used globally curated data, and to tackle the second, they developed a worldwide CLIP training framework. This framework follows OpenAI and Meta CLIP’s training settings and model architecture, including three additions: a multilingual text tokenizer, scaling of seen training pairs, and an analysis of minimal viable model capacity. To ensure generalizability, the training setup uses OpenAI CLIP’s ViT-L/14 and Meta CLIP’s ViT-H/14 models, with modifications for multilingual support. Moreover, studies on the minimal model expressivity reveal that even OpenAI’s ViT-L/14 struggles with the curse due to limited capacity, whereas ViT-H/14 serves as an inflection point, achieving notable gains in both English and non-English tasks.
Meta Clip 2 outperforms its English-only (1.0×) and non-English (1.3×) counterparts in both English and multilingual tasks when trained on ViT-H/14 with worldwide data and scaled seen pairs. However, the curse persists in non-scaled settings or with smaller models like ViT-L/14. Transitioning from English-centric metadata to worldwide equivalents is essential. For example, removing the English filter on alt-texts leads to a 0.6% drop in ImageNet accuracy, highlighting the role of language isolation. Replacing English metadata with merged worldwide metadata initially lowers English performance but boosts multilingual capabilities. Evaluations on zero-shot classification and few-shot geo-localization benchmarks show that scaling from 13B English to 29B worldwide pairs improves results, except for saturated performance in GeoDE.

In conclusion, researchers introduced Meta CLIP 2, the first CLIP model trained from scratch on worldwide image-text pairs. It shows that scaling metadata, curation, and training capacity can break the “curse of multilinguality”, enabling mutual benefits for English and non-English performance. Meta CLIP 2 (ViT-H/14) outperforms its English-only counterpart on zero-shot ImageNet (80.5% → 81.3%) and excels on multilingual benchmarks such as XM3600, Babel-IN, and CVQA with a single unified model. By open-sourcing its metadata, curation methods, and training code, Meta CLIP 2 enables the research community to move beyond English-centric approaches and embrace the potential of the worldwide multimodal web.
Check out the Paper and GitHub Page. Feel free to check out our GitHub Page for Tutorials, Codes and Notebooks. Also, feel free to follow us on Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter.

Sajjad Ansari is a final year undergraduate from IIT Kharagpur. As a Tech enthusiast, he delves into the practical applications of AI with a focus on understanding the impact of AI technologies and their real-world implications. He aims to articulate complex AI concepts in a clear and accessible manner.





