NVIDIA has released the Nemotron 3 family of open models as part of a full stack for agentic AI, including model weights, datasets and reinforcement learning tools. The family has three sizes, Nano, Super and Ultra, and targets multi agent systems that need long context reasoning with tight control over inference cost. Nano has about 30 billion parameters with about 3 billion active per token, Super has about 100 billion parameters with up to 10 billion active per token, and Ultra has about 500 billion parameters with up to 50 billion active per token.
Model family and target workloads
Nemotron 3 is presented as an efficient open model family for agentic applications. The line consists of Nano, Super and Ultra models, each tuned for different workload profiles.
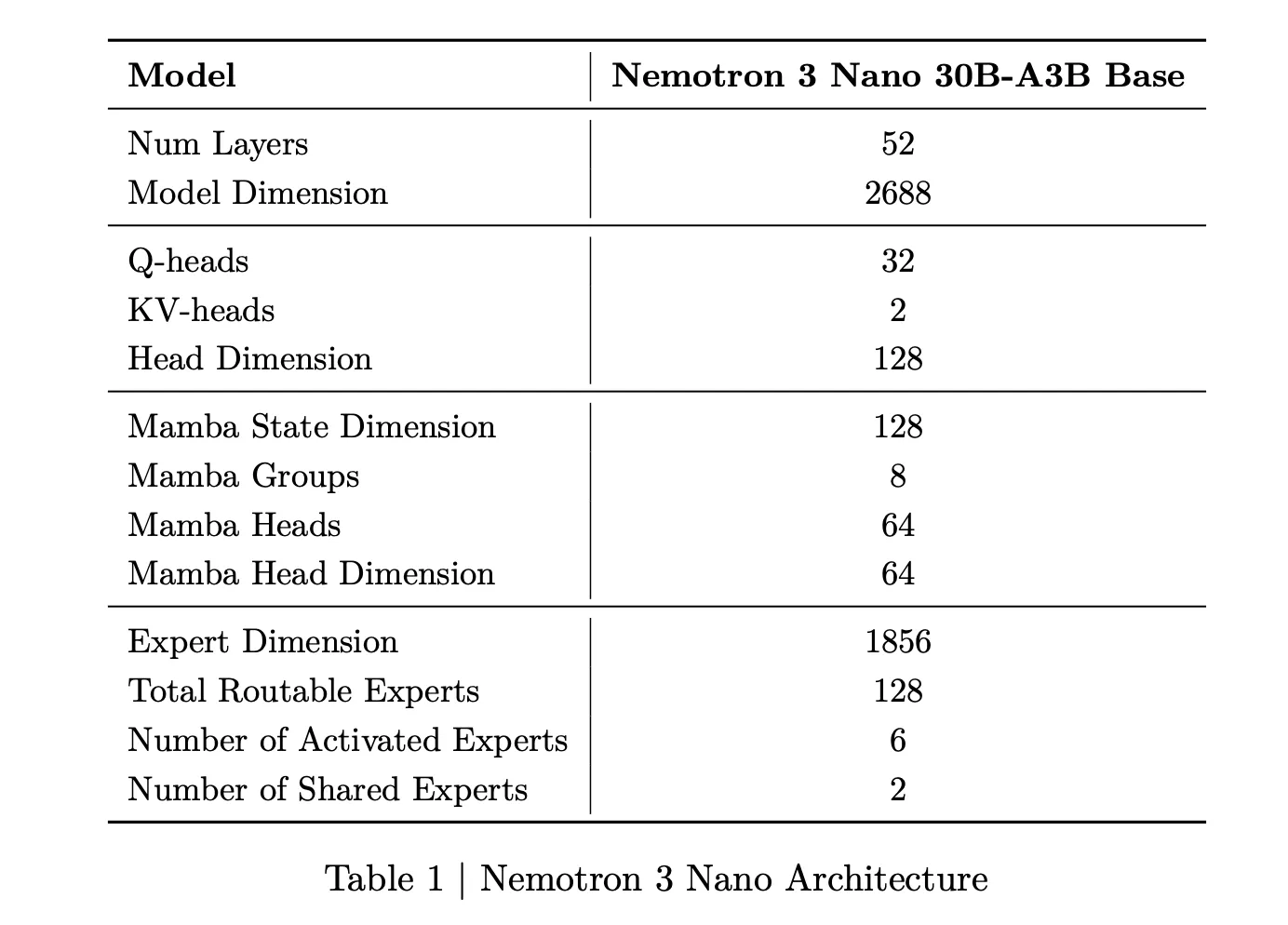
Nemotron 3 Nano is a Mixture of Experts hybrid Mamba Transformer language model with about 31.6 billion parameters. Only about 3.2 billion parameters are active per forward pass, or 3.6 billion including embeddings. This sparse activation allows the model to keep high representational capacity while keeping compute low.
Nemotron 3 Super has about 100 billion parameters with up to 10 billion active per token. Nemotron 3 Ultra scales this design to about 500 billion parameters with up to 50 billion active per token. Super targets high accuracy reasoning for large multi agent applications, while Ultra is intended for complex research and planning workflows.
Nemotron 3 Nano is available now with open weights and recipes, on Hugging Face and as an NVIDIA NIM microservice. Super and Ultra are scheduled for the first half of 2026.
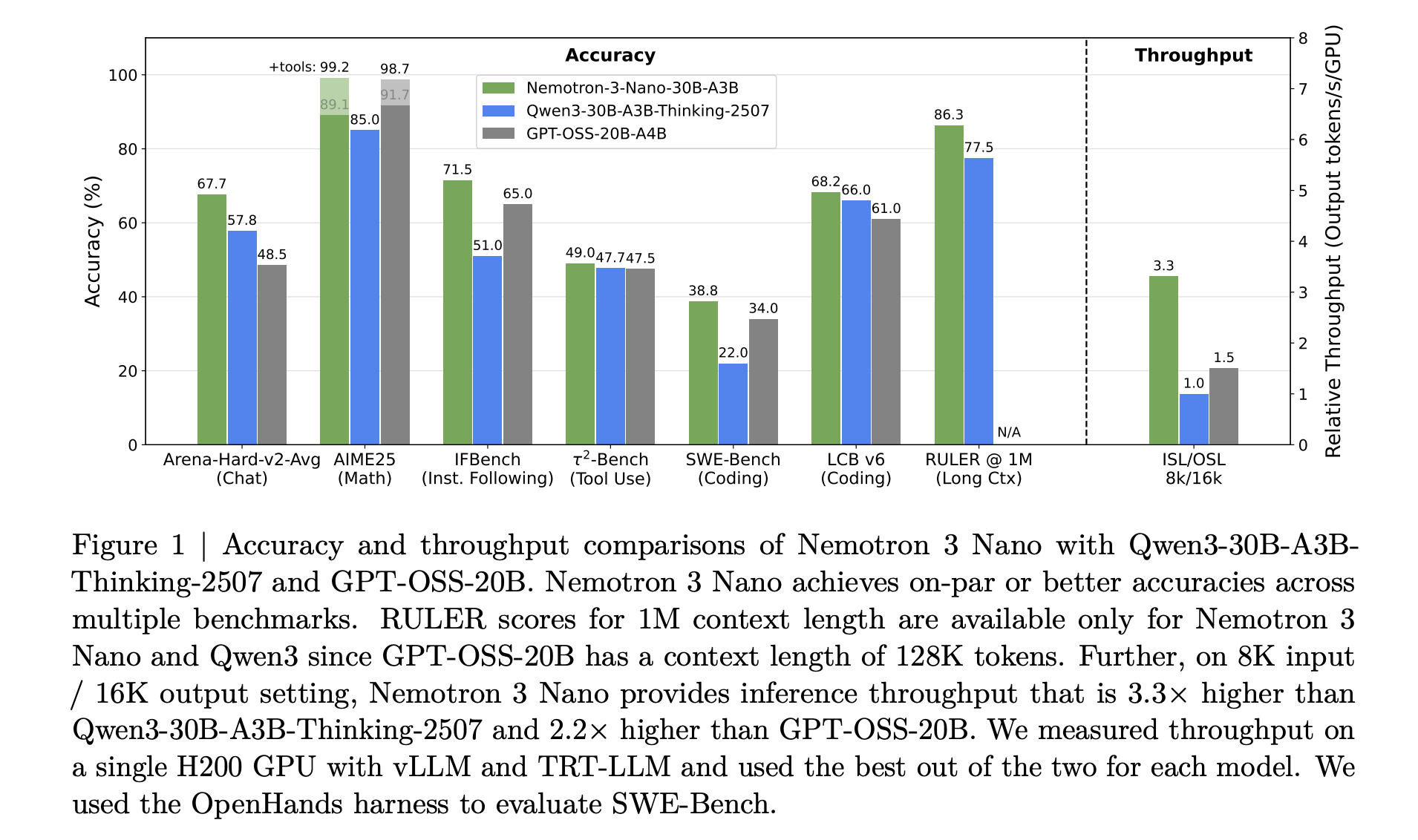
NVIDIA Nemotron 3 Nano delivers about 4 times higher token throughput than Nemotron 2 Nano and reduces reasoning token usage significantly, while supporting a native context length of up to 1 million tokens. This combination is intended for multi agent systems that operate on large workspaces such as long documents and large code bases.
Hybrid Mamba Transformer MoE architecture
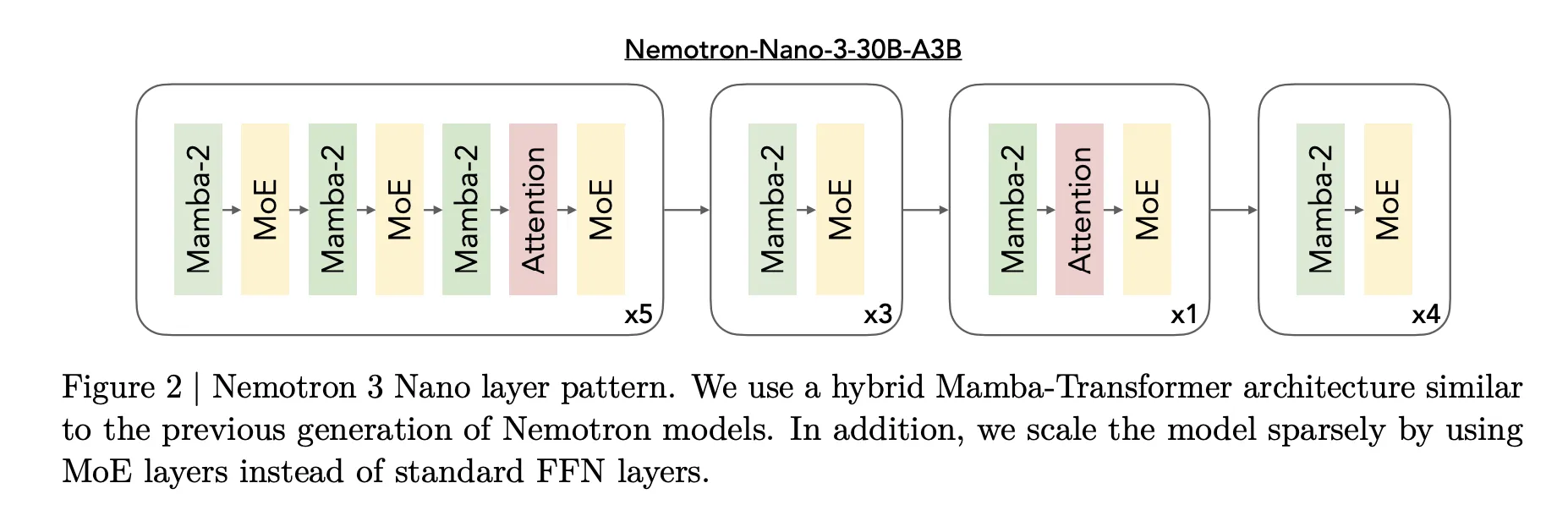
The core design of Nemotron 3 is a Mixture of Experts hybrid Mamba Transformer architecture. The models mix Mamba sequence blocks, attention blocks and sparse expert blocks inside a single stack.
For Nemotron 3 Nano, the research team describes a pattern that interleaves Mamba 2 blocks, attention blocks and MoE blocks. Standard feedforward layers from earlier Nemotron generations are replaced by MoE layers. A learned router selects a small subset of experts per token, for example 6 out of 128 routable experts for Nano, which keeps the active parameter count close to 3.2 billion while the full model holds 31.6 billion parameters.
Mamba 2 handles long range sequence modeling with state space style updates, attention layers provide direct token to token interactions for structure sensitive tasks, and MoE provides parameter scaling without proportional compute scaling. The important point is that most layers are either fast sequence or sparse expert computations, and full attention is used only where it matters most for reasoning.
For Nemotron 3 Super and Ultra, NVIDIA adds LatentMoE. Tokens are projected into a lower dimensional latent space, experts operate in that latent space, then outputs are projected back. This design allows several times more experts at similar communication and compute cost, which supports more specialization across tasks and languages.
Super and Ultra also include multi token prediction. Multiple output heads share a common trunk and predict several future tokens in a single pass. During training this improves optimization, and at inference it enables speculative decoding like execution with fewer full forward passes.
Training data, precision format and context window
Nemotron 3 is trained on large scale text and code data. The research team reports pretraining on about 25 trillion tokens, with more than 3 trillion new unique tokens over the Nemotron 2 generation. Nemotron 3 Nano uses Nemotron Common Crawl v2 point 1, Nemotron CC Code and Nemotron Pretraining Code v2, plus specialized datasets for scientific and reasoning content.
Super and Ultra are trained mostly in NVFP4, a 4 bit floating point format optimized for NVIDIA accelerators. Matrix multiply operations run in NVFP4 while accumulations use higher precision. This reduces memory pressure and improves throughput while keeping accuracy close to standard formats.
All Nemotron 3 models support context windows up to 1 million tokens. The architecture and training pipeline are tuned for long horizon reasoning across this length, which is essential for multi agent environments that pass large traces and shared working memory between agents.
Key Takeaways
- Nemotron 3 is a three tier open model family for agentic AI: Nemotron 3 comes in Nano, Super and Ultra variants. Nano has about 30 billion parameters with about 3 billion active per token, Super has about 100 billion parameters with up to 10 billion active per token, and Ultra has about 500 billion parameters with up to 50 billion active per token. The family targets multi agent applications that need efficient long context reasoning.
- Hybrid Mamba Transformer MoE with 1 million token context: Nemotron 3 models use a hybrid Mamba 2 plus Transformer architecture with sparse Mixture of Experts and support a 1 million token context window. This design gives long context handling with high throughput, where only a small subset of experts is active per token and attention is used where it is most useful for reasoning.
- Latent MoE and multi token prediction in Super and Ultra: The Super and Ultra variants add latent MoE where expert computation happens in a reduced latent space, which lowers communication cost and allows more experts, and multi token prediction heads that generate several future tokens per forward pass. These changes improve quality and enable speculative style speedups for long text and chain of thought workloads.
- Large scale training data and NVFP4 precision for efficiency: Nemotron 3 is pretrained on about 25 trillion tokens, with more than 3 trillion new tokens over the previous generation, and Super and Ultra are trained mainly in NVFP4, a 4 bit floating point format for NVIDIA GPUs. This combination improves throughput and reduces memory use while keeping accuracy close to standard precision.
Check out the Paper, Technical blog and Model Weights on HF. Feel free to check out our GitHub Page for Tutorials, Codes and Notebooks. Also, feel free to follow us on Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter.
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of Artificial Intelligence for social good. His most recent endeavor is the launch of an Artificial Intelligence Media Platform, Marktechpost, which stands out for its in-depth coverage of machine learning and deep learning news that is both technically sound and easily understandable by a wide audience. The platform boasts of over 2 million monthly views, illustrating its popularity among audiences.