

Introduction
Empowering large language models (LLMs) to fluidly interact with dynamic, real-world environments is a new frontier for AI engineering. The Model Context Protocol (MCP) specification offers a standardized gateway through which LLMs can interface with arbitrary external systems—APIs, file systems, databases, applications, or tools—without needing custom glue code or brittle prompt hacks each time. Still, leveraging such toolsets programmatically, with robust reasoning across multi-step tasks, remains a formidable challenge.
This is where the recent combination of MCP- RL (a reinforcement learning loop targeting MCP servers) and the open-source ART (Agent Reinforcement Trainer) library brings a paradigm shift: you can now have an agent probe, specialize, and self-optimize for any MCP service with minimal human design, no labeled data, and SOTA reliability. This article unpacks the exact mechanics, implementation pathways, and technical intricacies—down to code level—of this system.
What Is MCP- RL?
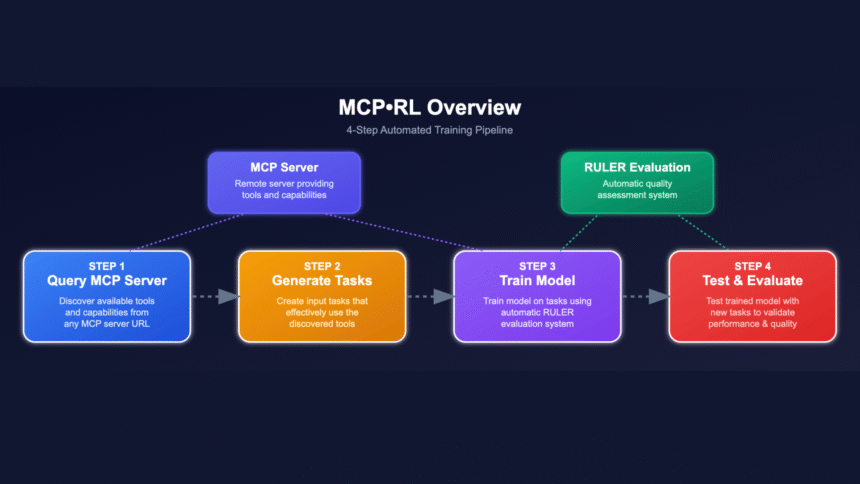
MCP- RL is a meta-training protocol built to let any LLM agent learn, through reinforcement learning (RL), to operate the toolset exposed by an MCP server. MCP-RL is part of the Agent Reinforcement Trainer (ART) project. Given only the server’s URL:
- The agent introspects the server, automatically discovering the available tools (functions, APIs, endpoints) with their schemas.
- Synthetic tasks are designed on-the-fly to encompass diverse tool applications.
- A relative scoring system (RULER) benchmarks agent performance, even without labeled gold data, on each trajectory.
- The agent is iteratively fine-tuned to maximize task success.
This means an LLM can gain proficiency on any conformant toolbacked server—APIs for weather, databases, file search, ticketing, etc.—just by pointing MCP- RL at the right endpoint.
ART: The Agent Reinforcement Trainer
ART (Agent Reinforcement Trainer) provides the orchestrated RL pipeline underlying MCP- RL, supporting most vLLM/HuggingFace-compatible models (e.g. Qwen2.5, Qwen3, Llama, Kimi) and a distributed or local compute environment. ART is architected with:
- Client/server separation: Inference and RL training decoupled; agents can be run from any client while training is automatically offloaded.
- Plug-and-play integration: Minimal intrusion to existing codebases; just hook ART’s client into your agent’s message-passing loop.
- GRPO algorithm: An improved RL fine-tuning approach for stability and learning efficiency, leveraging LoRA and vLLM for scalable deployment.
- No labeled data required: Synthetic scenarios and relative reward (RULER) system entirely replace hand-crafted datasets.
Code Walkthrough: Specializing LLMs with MCP- RL
The essence of the workflow is distilled in the following code excerpt from ART’s documentation:
from art.rewards import ruler_score_group
# Point to an MCP server (example: National Weather Service)
MCP_SERVER_URL = "https://server.smithery.ai/@smithery-ai/national-weather-service/mcp"
# Generate a batch of synthetic scenarios covering server tools
scenarios = await generate_scenarios(
num_scenarios=24,
server_url=MCP_SERVER_URL
)
# Run agent rollouts in parallel, collecting response trajectories
# Each trajectory = (system, user, assistant messages...)
# Assign rewards to each group using RULER's relative scoring
scored_groups = []
for group in groups:
judged_group = await ruler_score_group(group)
scored_groups.append(judged_group)
# Submit grouped trajectories for RL fine-tuning (GRPO)
await model.train(scored_groups)
Explanation:
- Scenario Synthesis: No human-crafted tasks needed.
generate_scenariosauto-designs diverse prompts/tasks based on the tools discovered from the MCP server. - Rollout Execution: The agent runs, invoking tool calls via MCP, acquiring trajectories of step-wise tool usage and outputs.
- RULER Scoring: Instead of a static reward, RULER uses relative evaluation within each batch to automatically scale rewards, robustly handling variable difficulty and task novelty.
- Training Loop: Batches of trajectories and rewards are sent to the ART server, where LoRA adapters are incrementally re-trained using the policy gradient algorithm GRPO.
The loop repeats—each cycle making the agent more proficient at combining the server’s tools to solve the synthetic tasks.
Under the Hood: How MCP- RL Generalizes
- Tool Discovery: The MCP interface typically exposes OpenAPI-compliant schemas, which the agent parses to enumerate all callable actions and their signatures—no assumptions about domain specifics.
- Scenario Generation: Templates or few-shot language model prompts can be used to bootstrap tasks that sample representative usages (atomic or complex API compositions).
- Feedback without Gold Data: RULER’s innovation is batchwise comparison, giving higher scores to more successful behaviors within the current set—this self-adapts across new tasks or noisy environments.
- Synthetic → Real Task Bridge: Once the agent is proficient on constructed tasks, it generalizes to actual user demands, since the coverage of tool usage is designed to be broad and combinatorial.
Real-World Impact and Benchmarks
- Minimal Setup: Deployable with any MCP server—just the endpoint, no internal code or access required.
- General Purpose: Agents can be trained to use arbitrary toolsets—weather, code analysis, file search, etc.
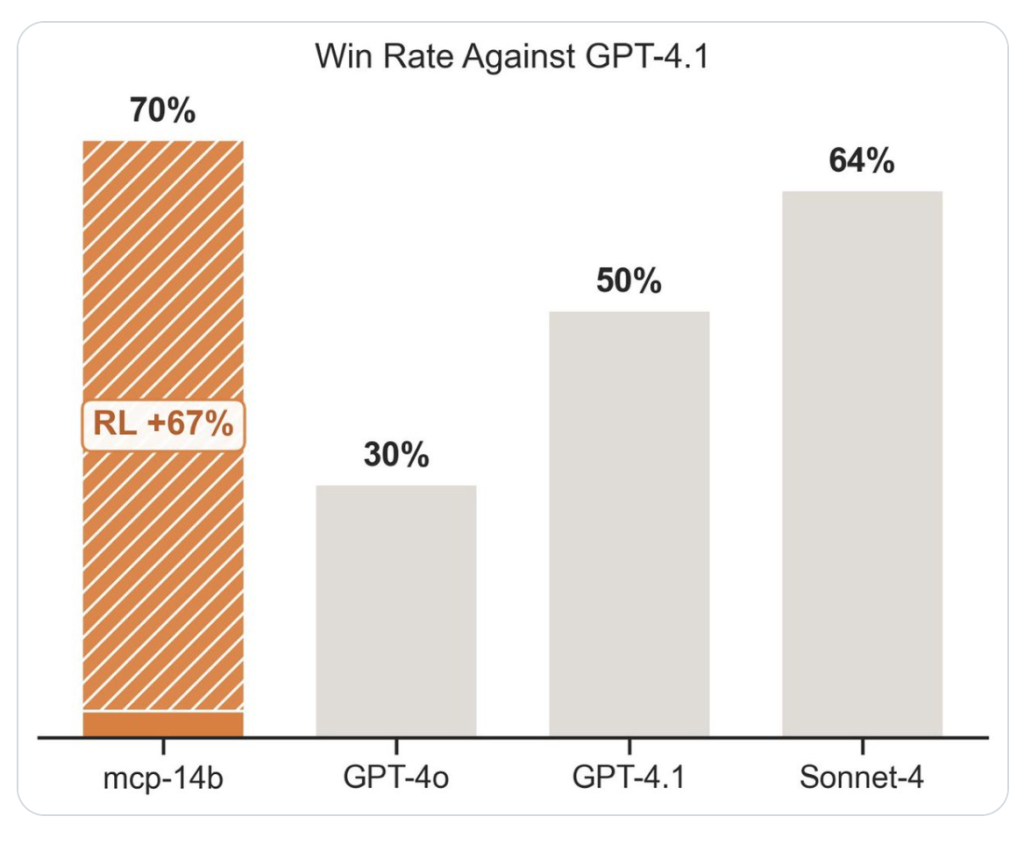
- State-of-the-Art Results: Matched or outperformed specialist agent baselines in 2/3 public benchmarks.
- Zero Labeled Data: The approach provides a scalable path for agentic RL on-the-fly, applicable even where expert demonstrations are impossible to procure.
Architectural Overview
| Component | Description |
|---|---|
| ART Client | Orchestrates agent rollouts, sends/receives messages, batches rewards |
| ART Server | Handles inference and RL training loop, manages LoRA checkpoints |
| MCP Server | Exposes the toolset, queried by agent during each task |
| Scenario Engine | Auto-generates synthetic diverse task prompts |
| RULER Scorer | Relative reward assignment for each group of trajectories |
Practical Integration
- Installation:
pip install openpipe-art - Flexibility: ART works with local or cloud compute, via vLLM or compatible backends.
- Debugging Tools: Integrated with W&B, Langfuse, OpenPipe for observability.
- Customizability: Advanced users can tune scenario synthesis, reward shaping, batch sizes, LoRA configs.
Summary
The combination of MCP- RL and ART abstracts away years of RL automation design, letting you convert any LLM into a tool-using, self-improving agent, domain-agnostic and without annotated training data. Whether your environment is public APIs or bespoke enterprise servers, the agent learns on-the-job and achieves scalable, robust performance.
For further details, practical example notebooks, and up-to-date benchmarks, visit the ART repository and its [MCP- RL-specific training examples]

Michal Sutter is a data science professional with a Master of Science in Data Science from the University of Padova. With a solid foundation in statistical analysis, machine learning, and data engineering, Michal excels at transforming complex datasets into actionable insights.





